Engineering personalization at scale: Inside Formation’s planning algorithm
![]() May 1, 20255 min read
May 1, 20255 min read

At Formation, we spend a lot of time thinking about how to make interview prep truly personal — and how to build the systems that can support it at scale.
This post is the first in a new series where we’ll share the technical challenges our engineering team is solving to make that vision real. We’re pulling back the curtain on how our systems work, not at the marketing level, but at the level of real-world complexity, tradeoffs, and decisions.
We’re starting with a problem that sits at the heart of our model: how do you dynamically generate a personalized plan for every Fellow, every week, when schedules, skills, and group dynamics are constantly shifting?
And how do you do it fast enough, flexibly enough, and accurately enough that people actually progress faster than they would with traditional methods?
The team behind the work
The initial version of the planning system was built collaboratively by engineers who had worked on large-scale, complex systems at companies like Meta.
Key contributors included:
The system evolved through real-world iteration: adjusting tradeoff weights, tuning matching parameters, and surfacing practical insights on human scheduling behavior that no theoretical model would have predicted.
It’s still evolving — and it’s still one of the most complex, interesting parts of the platform.
The challenge: dynamic planning, not static scheduling
In the earliest days of Formation, scheduling was done manually. Our founder, Sophie, spent full Sundays arranging sticky notes on a whiteboard, mapping fellows to sessions by hand.
As the program grew, manual scheduling became unmanageable. It wasn’t just time-intensive. It was error-prone and couldn’t flex to the reality that people’s lives, skills, and availability are always changing.
The first step to solve the problem was straightforward automation: scripts to gather availability and basic tools to prevent double-booking. But true scalability demanded more than automation.
It demanded a system designed to model learning as a dynamic, constantly shifting process — and to generate plans optimized for this week’s state, not last week’s assumptions.
At a high level, Formation’s planning challenge looks simple:
- Every week, generate a full schedule of sessions pairing fellows with mentors.
- Each fellow's schedule should reflect their current skills and the ideal next areas to focus on.
- Sessions should be small group or 1:1 and can be peer or mentor-led, dynamically formed based on availability, skill levels, and history.
In practice, the problem is much closer to solving a large-scale dynamic matching and ranking problem:
- Availability is messy and changes weekly.
- Skill levels are multidimensional and probabilistic, not cleanly tiered.
- Preferences (session pacing, back-to-back vs. spaced out, mentor pairing history) need to be respected.
- Mentor expertise varies across dozens of micro-skills.
- Drop-off risks, historical conflicts, and session redundancies need to be avoided.
Every week is a fresh recomputation, there’s no carryover assumptions from last week’s state. There’s no "correct" solution. The goal is to optimize across multiple competing axes under real-world constraints.
Mapping messy, real-world data
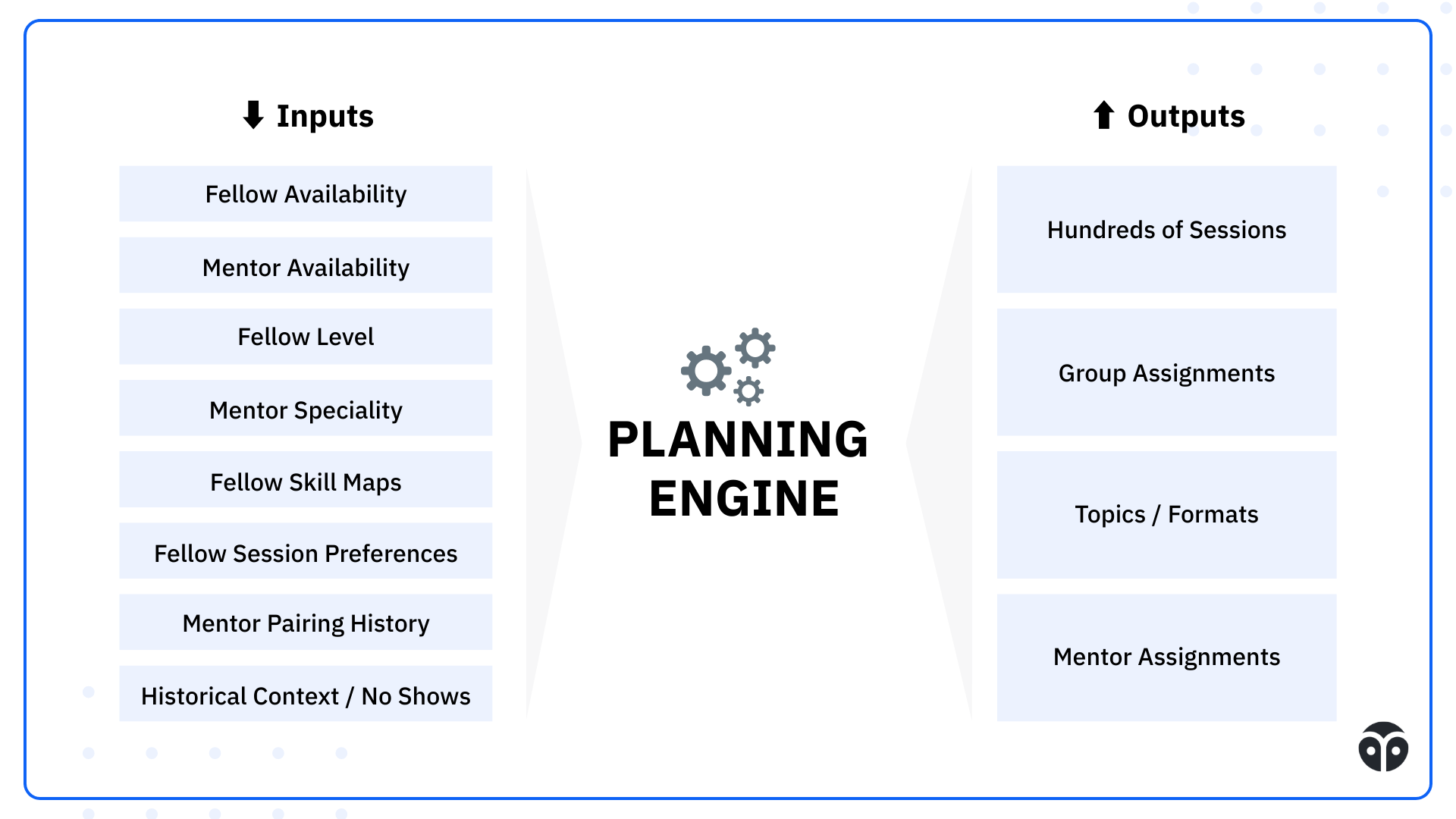
Each week, the planning algorithm ingests a large, messy set of real-world data:
- Availability: Fellows and mentors submit explicit availability and integrate Google Calendars for real-time conflict detection.
- Skill maps: Each Fellow’s proficiency is tracked across dozens of technical micro-skills. Skills are selected at a granularity that reflects 1–2 weeks of potential growth.
- Level probabilities: Rather than tagging Fellows as "junior" or "mid," we track a probability distribution across levels, reflecting the uncertainty and subjectivity in leveling.
- Mentor expertise and session history: Prior session history, topics covered, and mentor topic strength are all factored into future matching.
- Preferences and constraints: Session format preferences, historical avoidance lists, session pacing needs, and expected drop-off risk models.
Importantly, none of these are treated as hard constraints unless explicitly necessary. The system expects noise, overlap, and imperfect data — and is built to operate within it.
From these inputs, the planning algorithm generates a full schedule for the week ahead:
- Hundreds of sessions
- Groupings of fellows by skill level and topic readiness
- Assigned mentors based on expertise and session fit
- Tailored topics and formats based on learning goals
No two fellows follow the same path.
Some individuals accelerate quickly on one concept and move ahead, while others may require deeper reinforcement on a different topic.
Because the system resets and recalibrates every week, fellows' journeys can actually respond to their real progress, not be locked into an arbitrary calendar.
Building the algorithm
Planning at Formation isn’t about finding a single correct answer. There is no one "best" schedule. It’s a ranking and matching problem, where every decision involves weighing competing priorities:
- Should skill-level matching take precedence over group size?
- Should we favor mentor expertise over fellow schedule convenience?
- Should we build buffers into sessions to account for dropouts?
There were two obvious architectural approaches:
- Global optimization: generate and score all possible sessions and combinations, pick the global optimum.
- Greedy matching: iteratively build the best next session given the current state, adjusting dynamically.
After exploring different approaches, we chose a greedy algorithm model. Instead of trying to compute every possible plan, which would be computationally intractable, we build the best next session at each step, dynamically updating the available pool.
A greedy algorithm allows the system to:
- Build sessions step-by-step based on real-time best-fit calculations.
- Dynamically adjust to partial solutions (e.g., if a mentor's availability tightens midway through planning).
- Embed soft-priority handling (e.g., sometimes level matching matters more than perfect topic sequencing).
Each planning cycle involves selecting the next-best session given current availability, skills, and matching rules, then recalculating downstream options based on that assignment. It’s fast, scalable, and adaptable.
This approach fits the reality of the problem:
- Inputs are fuzzy, incomplete, and shifting.
- Constraints are real but flexible.
- Priorities often conflict, and human judgment matters.
Every threshold — how similar fellows need to be, how tightly topics must align, how much group size can flex — reflects deliberate judgment, not arbitrary defaults. It’s an engineered system, but it’s also a product of careful thinking about people, not just data.
The tradeoff: there’s no guarantee of a global optimum.
The upside: the system produces high-quality, real-world-usable schedules under time constraints that actually matter.
Faster progress through real personalization
This has allowed us to create an environment where fellows can move faster and more effectively toward their goals.
Each fellow’s learning path evolves weekly:
- Rapid mastery of a topic can immediately lead to faster advancement.
- Struggles on a concept trigger reinforcement in the next planning cycle.
- Fellows aren’t gated by cohort progress — they move based on their own learning, not the average.
Traditional models batch learners into large groups and lock them into fixed timelines. Formation’s model recalibrates constantly. The planning algorithm makes this recalibration possible, without requiring manual human oversight at an unscalable cost.
Engineering for real-world impact
Formation’s planning algorithm is one example of the types of technical problems we take on: messy, high-variance systems challenges where success is measured not by theoretical optimality, but by building robust, flexible systems that survive real-world complexity.
It’s system design, optimization, education theory, and human behavior modeling — all colliding in one engine.
And it’s just one part of the broader technical foundation we’re building.